


Cuando no monitoreas tu servidor Odoo, los problemas llegan como relámpagos: la app se vuelve lenta, aparecen errores 502/504, alguien reinicia servicios “a ver si mejora” y terminas comprando más servidor a ciegas. Este blog te cuenta cómo romper ese ciclo con plataformas APM: poner “ojos” sobre la aplicación, PostgreSQL e infraestructura, correlacionar métricas, logs y trazas, y recibir alertas tempranas antes de que el negocio sufra.
Importancia del monitoreo
Monitorear no es “mirar gráficos”, es gestionar riesgos: disponibilidad, tiempos de respuesta, costos de infraestructura y satisfacción de usuarios. Sin datos confiables, solo reaccionas cuando ya es tarde.
En simple:
- Observabilidad completa (métricas, logs, eventos y trazas) para entender app, base de datos y sistema operativo como un todo.
- Alertas preventivas (CPU, RAM, I/O, latencia, errores) que te avisan antes del incidente.
- Decisiones con evidencia: optimizar índices, escalar workers o ajustar PostgreSQL con datos, no por intuición.
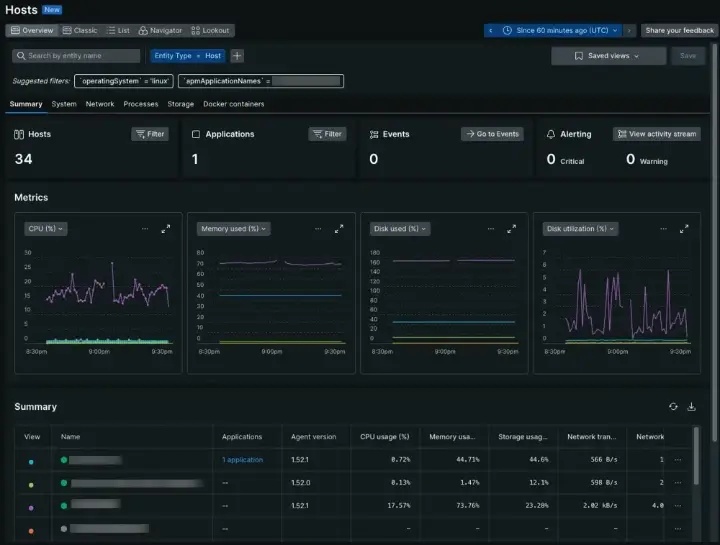
¿Cuándo necesito monitorear mi servidor?
Monitorear “siempre” suena bien, pero la verdad es que hay momentos y señales que lo vuelven imprescindible. Si identificas cualquiera de los puntos siguientes, es hora de instrumentar métricas, logs, trazas y alertas.
- Usuarios reportan lentitud al validar facturas, abrir asientos o generar ventas.
- Caídas intermitentes o reinicios “misteriosos” de servicios/contendores.
- Procesos masivos (libros, facturación, importaciones) que tardan cada vez más.
- Aumenta el número de tickets por tiempos de espera o errores 502/504.
¿Qué es un APM?
Un APM (Application Performance Monitoring) es una plataforma que te muestra, en una sola vista, cómo se comporta tu aplicación por dentro: qué transacciones son lentas, qué consultas a la base consumen más tiempo, qué errores ocurren y cómo impacta todo eso en el servidor. En lugar de “adivinar”, un APM mide, correlaciona y alerta de la siguiente manera:
- Traza transacciones: mide latencia (p50/p95/p99), throughput y errores por ruta/función.
- Visibilidad de base de datos: identifica top queries por tiempo/llamadas y su impacto.
- Logs en contexto: conecta cada error con su traza y la métrica que lo disparó.
- Infraestructura y contenedores: CPU, memoria, disco, red y reinicios, ligados a las transacciones.
- Alertas inteligentes: umbrales y detección de anomalías para avisarte antes del incidente.
- Dashboards y SLOs: paneles listos para negocio y operación (lo que importa de verdad).

¿Por qué New Relic?
Si solo miras CPU y “está alto”, sabes el síntoma pero no la causa. New Relic destaca porque te lleva de la alerta al endpoint, a la consulta SQL y al log exacto en uno o dos clics. Esa trazabilidad reduce drásticamente el tiempo para entender y resolver incidentes en Odoo.
Lo que lo hace distinto
- Observabilidad unificada (MELT): métricas, eventos, logs y trazas en una sola vista. No saltas entre 3–4 herramientas diferentes.
- Correlación inmediata: una alerta de latencia te lleva a la transacción lenta, muestra la consulta a PostgreSQL y abre el log en contexto.
- Listo para tu stack: integraciones para Python/Odoo, PostgreSQL, Nginx, Docker/Kubernetes y sistema operativo, sin “pegamento” artesanal.
- Dashboards y alertas en minutos: paneles base reutilizables y alertas por horario de negocio (útil para evitar sustos en horas pico).
- Escala sin perder control: auto-descubrimiento de contenedores y metadata para ver qué servicio consume qué recurso.
Beneficios concretos para Odoo
- Diagnóstico de cuellos de botella en reportes, facturación, transferencias e integraciones: del botón que presiona el usuario a la consulta pesada.
- Menos caídas y tiempos muertos: detecta picos de memoria/I-O y bloqueos de queries antes de que tumben el servidor.
- Decisiones con datos: ¿optimizar SQL, subir workers, ajustar autovacuum o cambiar almacenamiento? New Relic te muestra dónde rinde más cada acción.
- Ahorro operativo: evitas sobreaprovisionar servidores “a ciegas” y reduces el MTTD/MTTR del equipo.
Casos de monitoreo
A continuación, te muestro diferentes incidentes donde se tuvo que monitorear el servidor de diferentes clientes. Las horas, causas y acciones provienen del reporte de incidentes y capturas (gráficas de memoria/CPU, logs y consultas) incluidos en cada caso.
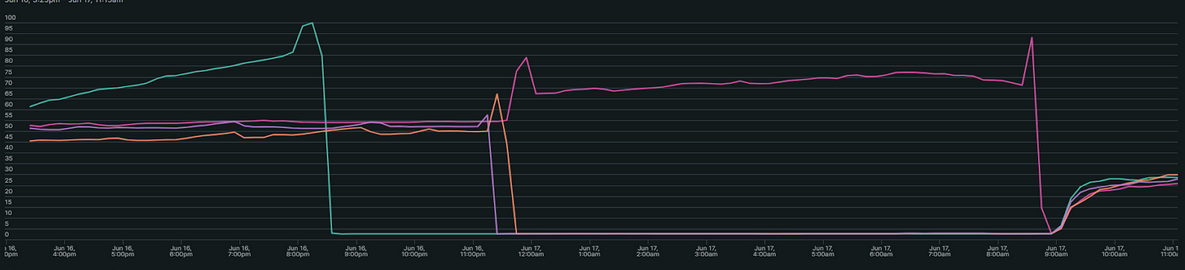
Caso 1 — Saturación de memoria en aplicaciones
Qué pasó. Los cuatro nodos de aplicación alcanzaron 100 % de RAM, obligando a reinicios. Impacto: interrupción total, pérdida de sesiones. Causa raíz: reportes contables sobre períodos extensos, sin paginación ni filtros. Acción inmediata: reinicio de servicios.
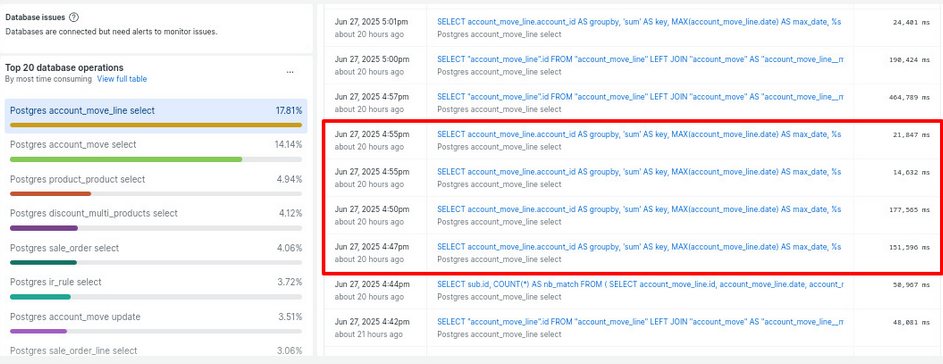
Caso 2 — Bloqueos de queries en registros contables
Qué pasó. Al abrir apuntes con filtros y ejecutar procesos contables, múltiples consultas a account_move y account_move_line entraron en lock wait y se bloquearon entre sí. Impacto: UI > 2 min, errores 502. Acciones: abortar consultas y reinicio.
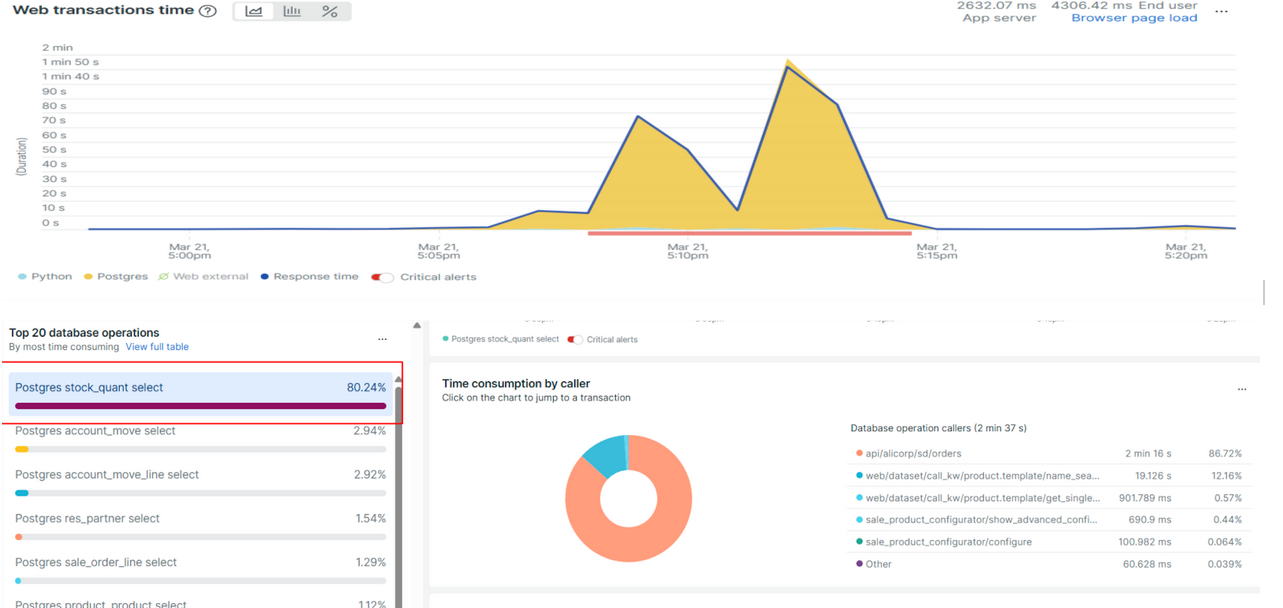
Caso 3 — Lentitud por procesos de stock
Qué pasó. Al consultar la disponibilidad de inventario, el sistema lanzó cálculos que normalmente toman menos de un segundo y, en los picos, tardaron más de 20 segundos. Impacto: Las pantallas de stock y ventas se volvieron muy lentas; algunas operaciones no terminaron y los usuarios quedaron esperando. Acción inmediata: Se detuvieron esas tareas y se reinició el servicio para recuperar la operación.
Conclusiones
Monitorear Odoo no es opcional cuando el negocio crece: es la diferencia entre reaccionar a caídas y anticiparse con datos. La observabilidad convierte síntomas (lentitud, errores, picos de CPU/RAM/I/O) en causas claras y acciones concretas.
Puntos clave que nos deja el análisis:
-
Mide por capas (aplicación, infraestructura, base de datos y orquestación) y correlaciónalo todo; ahí aparece la causa real.
- KPIs mínimos para operar con calma: latencia p95, tasa de errores, uso de CPU/RAM, iowait, conexiones a PostgreSQL y “top queries” por tiempo/llamadas.
- Decisiones con evidencia: antes de comprar más servidores, identifica si conviene optimizar SQL/índices, paginación/batching, ajustar autovacuum/pgbouncer o separar workers.
- New Relic acelera el ciclo “ver → entender → corregir” con métricas, logs y trazas en contexto; menos herramientas, más claridad.

¿Quieres tener tu odoo bajo control?
Te ayudamos a instrumentar New Relic, definir KPIs y aplicar buenas prácticas para que los picos de uso no se conviertan en incidentes.